Using Wave AI
There are currently two ways to use Wave AI: interactively, and via the /chat command.Interactive
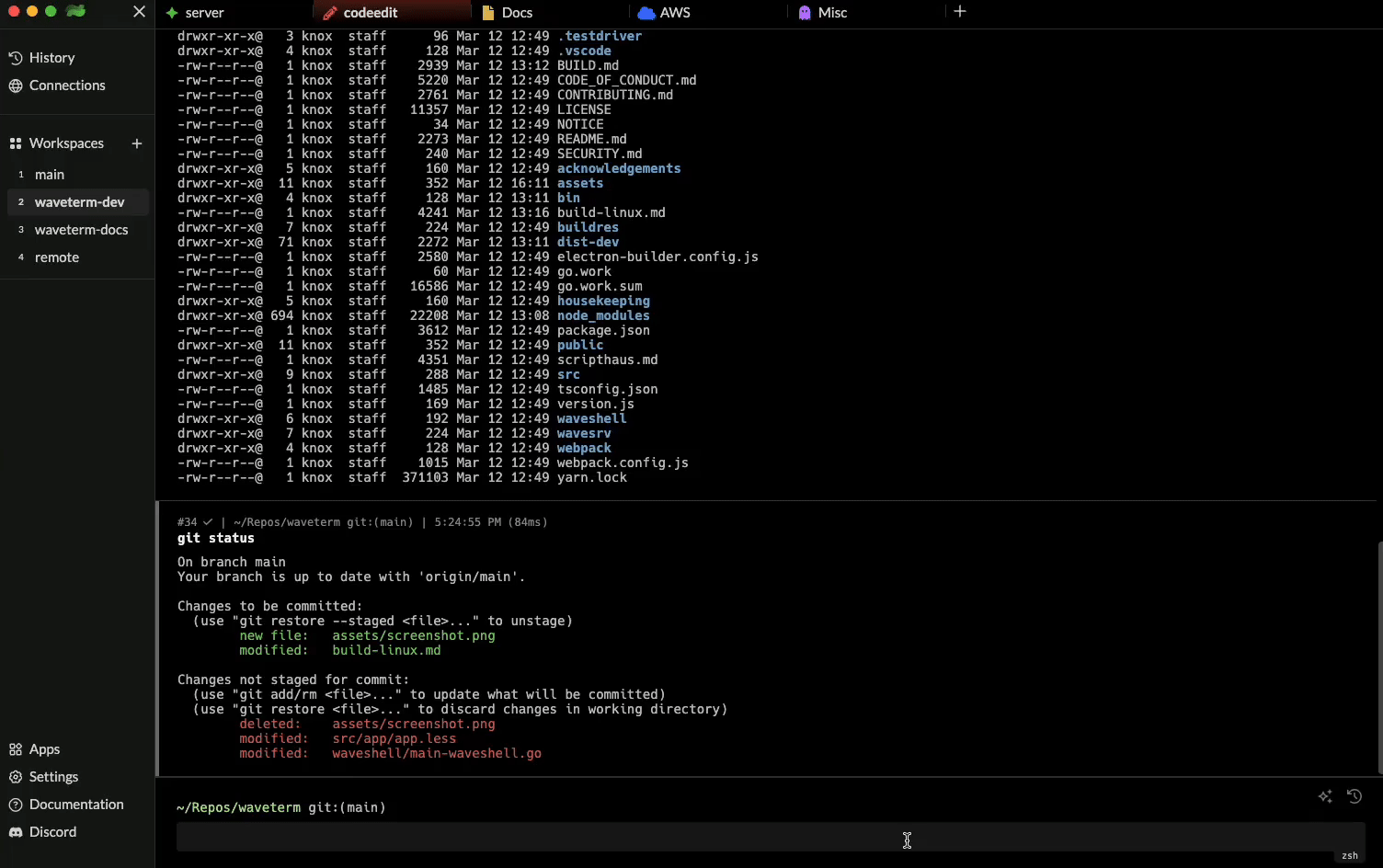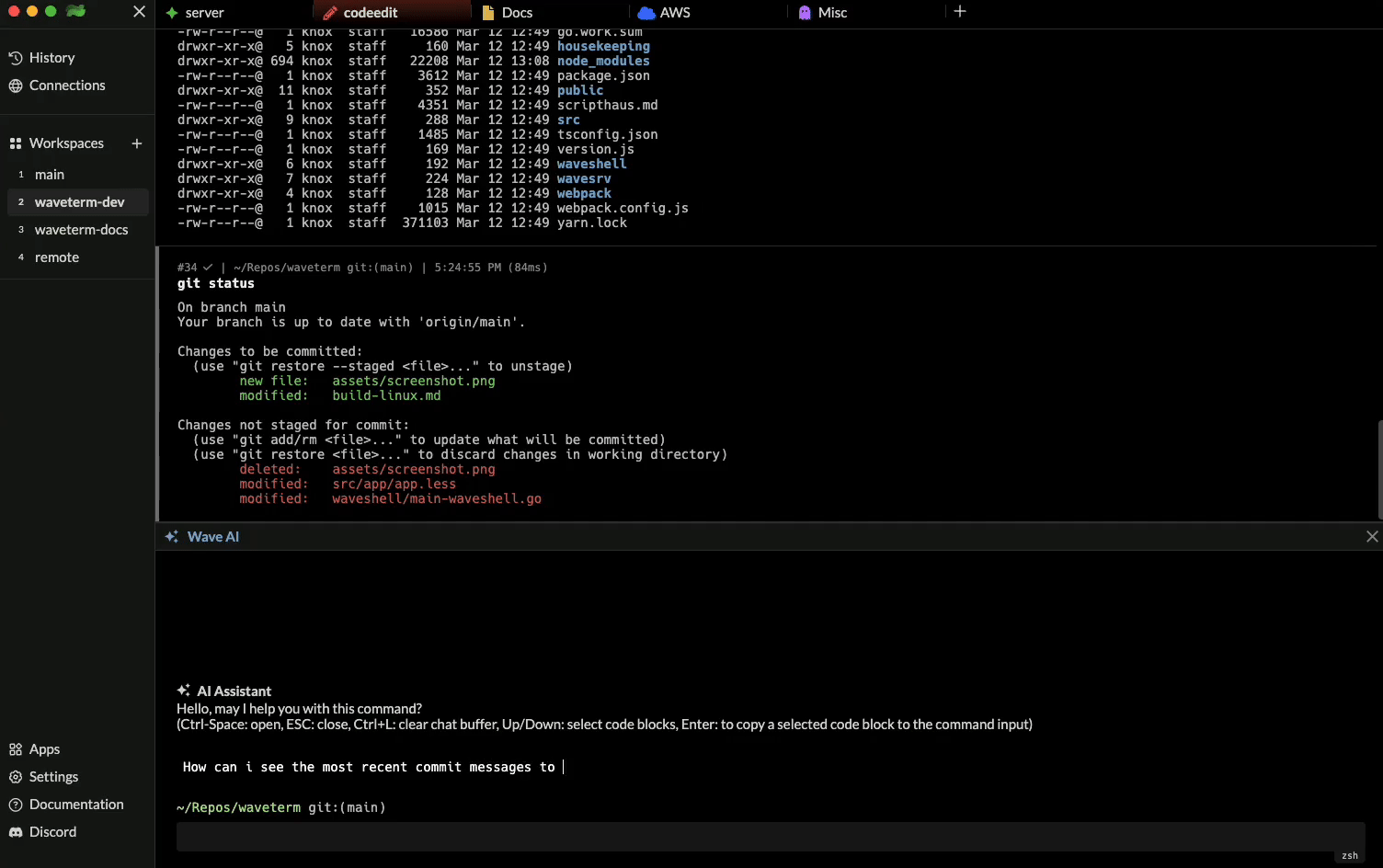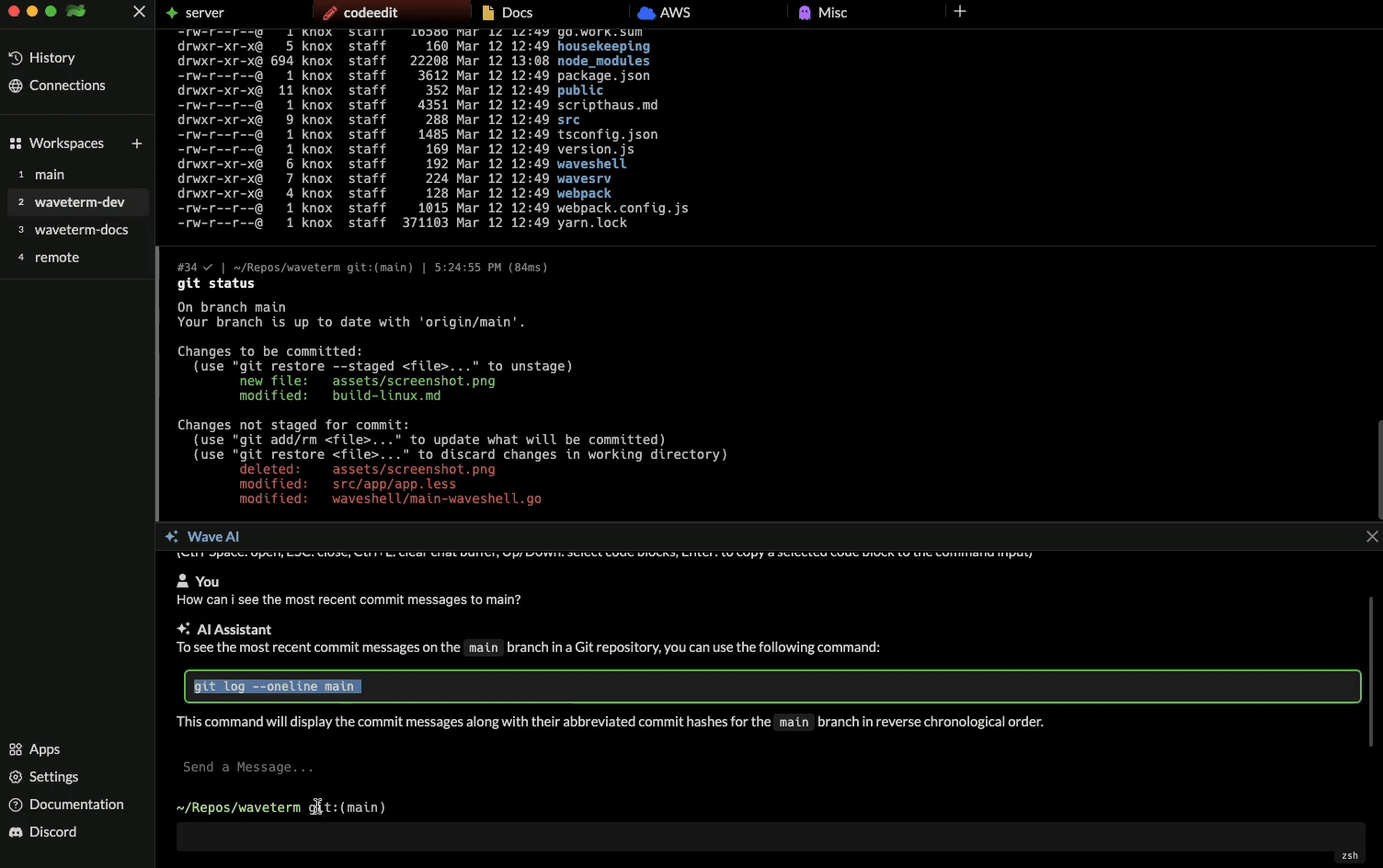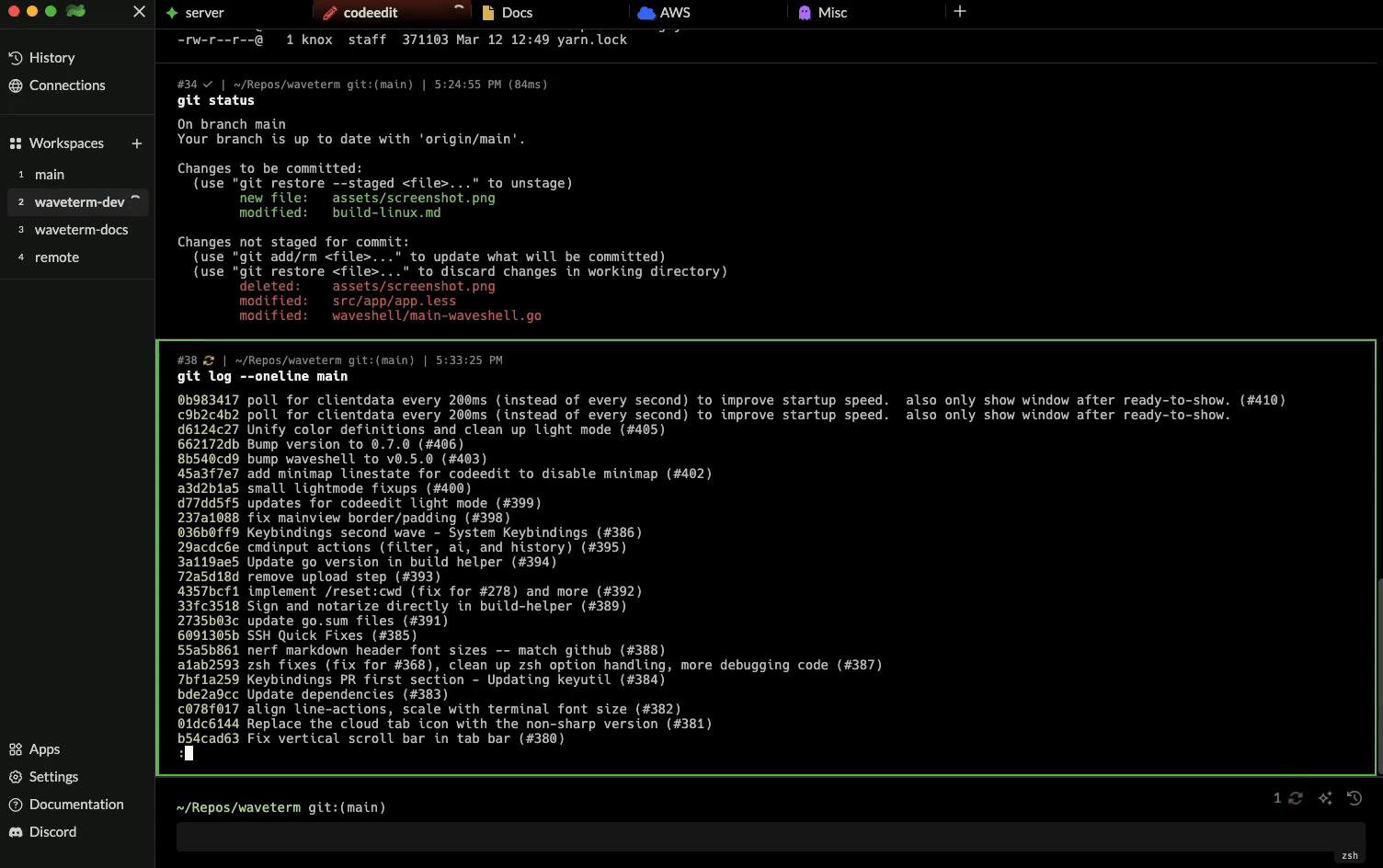
The first way is by clicking the “Wave AI” button in the command box or using the shortcutctrl + space. This will open an interactive chat session where you can have a continuous conversation with the AI assistant.
Chat command
Alternatively, you can use the /chat command followed by your question to get a quick answer from the terminal.Customization
By default, Wave will proxy your requests through our cloud servers to OpenAI. However, you can customize your experience by modifying the following settings in the UI or by using the /client:set command:aiapitoken:Set your own OpenAI API key if you prefer not to use Wave’s default configuration. Note that your API token will never be sent to Wave’s cloud servers. When you provide your own API key, all future requests will be sent directly to OpenAI or any other endpoint you specify usingaibaseurl.aibaseurl:If you want to use other 3rd party LLM providers compatible with the OpenAI API, you can change the base URL. You will also want to set youraiapitokenin conjunction with the base url to use a different service if that service requires one.aimaxchoices:This option determines the number of different response variations the AI model will generate for each query. Increasing this value will provide more diverse responses, while decreasing it will make the model’s output more focused and consistent.aimaxtokens:This setting allows you to control the maximum number of tokens (words or word pieces) that the AI model will generate in a single response.aimodel:By default, Wave uses ChatGPTs gpt-3.5-turbo model, however you can choose a different model if you wish. You will need to also setaiapitokenif you choose to use another ChatGPT model. Also, when configuring other third-party services you will want to change this setting to the appropriate model.aitimeout:Specify the maximum time (in milliseconds) to wait for a response from the AI service before timing out. The default value is 10 seconds. This setting is particularly useful when configuring and troubleshooting LLM providers, as response times can vary significantly depending on the hardware constraints of the system running the model.
Third-Party LLM Support (BYOLLM)
Wave AI supports various third-party Large Language Model providers, allowing you to bring your own LLM (BYOLLM) and choose the model that best suits your needs and preferences. This section provides a comprehensive list of providers that are compatible with Wave AI, enabling you to make an informed decision based on your specific requirements and concerns. To get started with a specific integration, simply click on the provider to access the setup instructions and configuration details for that particular LLM.Supported LLM Providers:
Local LLM Providers
Local LLM Providers
Cloud-based LLM Providers
Cloud-based LLM Providers